
As our world is getting more global and dynamic, businesses are more and more dependent on data for making informed, objective and timely decisions. However, as of now, unleashing the full potential of organisational data is often a privilege of a handful of data scientists and analysts. Most employees don’t master the conventional data science toolkit (SQL, Python, R etc.). To access the desired data, they go via an additional layer where analysts or BI teams “translate” the prose of business questions into the language of data. The potential for friction and inefficiency on this journey is high — for example, the data might be delivered with delays or even when the question has already become obsolete. Information might get lost along the way when the requirements are not accurately translated into analytical queries. Besides, generating high-quality insights requires an iterative approach which is discouraged with every additional step in the loop. On the other side, these ad-hoc interactions create disruption for expensive data talent and distract them from more strategic data work, as described in these “confessions” of a data scientist:
"When I was at Square and the team was smaller we had a dreaded “analytics on-call” rotation. It was strictly rotated on a weekly basis, and if it was your turn up you knew you would get very little “real” work done that week and spend most of your time fielding ad-hoc questions from the various product and operations teams at the company (SQL monkeying, we called it). There was cutthroat competition for manager roles on the analytics team and I think this was entirely the result of managers being exempted from this rotation — no status prize could rival the carrot of not doing on-call work."[1]
Indeed, wouldn’t it be cool to talk directly to your data instead of having to go through multiple rounds of interaction with your data staff? This vision is embraced by conversational interfaces which allow humans to interact with data using language, our most intuitive and universal channel of communication. After parsing a question, an algorithm encodes it into a structured logical form in the query language of choice, such as SQL. Thus, non-technical users can chat with their data and quickly get their hands on specific, relevant and timely information, without making the detour via a BI team. In this article, we will consider the different implementation aspects of Text2SQL and focus on modern approaches with the use of Large Language Models (LLMs), which achieve the best performance as of now (cf. [2]; for a survey over alternative approaches beyond LLMs, readers are referred to [3]). The article is structured according to the following “mental model” of the main elements to consider when planning and building an AI feature:

Figure 1: Mental model of an AI feature
Let’s start with the end in mind and recap the value — why you would build a Text2SQL feature into your data or analytics product. The three main benefits are:
- Business users can access organisational data in a direct and timely way.
- This relieves data scientists and analysts from the burden of ad-hoc requests from business users and allows them to focus on advanced data challenges.
- This allows the business to leverage its data in a more fluid and strategic way, finally turning it into a solid basis for decision making.
Now, what are the product scenarios in which you might consider Text2SQL? The three main settings are:
- You are offering a scalable data/BI product and want to enable more users to access their data in a non-technical day, thus growing both the usage and the user base. As an example, ServiceNow has integrated data queries into a larger conversational offering, and Atlan has recently announced natural-language data exploration.
- You are looking to build something in the data/AI space to democratise data access in companies, in which case you could potentially consider an MVP with Text2SQL at the core. Providers like AI2SQL and Text2sql.ai are already making an entrance in this space.
- You are working on a custom BI system and want to maximise and democratise its use in the individual company.
In the following, we will consider the data, algorithm, user experience as well as the relevant non-functional requirements of a Text2SQL feature. The article is written for product managers, UX designers and those data scientists engineers who are at the beginning of their Text2SQL journey. For these folks, it provides not only a guide to get started, but also a common ground of knowledge for discussions around the interfaces between product, technology and business, including the related trade-offs. If you are already more advanced in your implementation, the references at the end provide a range of deep dives to explore.
1. Data
Any machine learning endeavour starts with data, so we will start by clarifying the structure of the input and target data that are used during training and prediction. Throughout the article, we will use the following Text2SQL flow as our running representation, and highlight the currently considered components and relationships in yellow.

Figure 2: In this Text2SQL representation, data-related elements and relations are marked in yellow.
1. 1 Format and structure of the data
Typically, a raw Text2SQL input-output pair consists of a natural-language question and the corresponding SQL query, for example:
Question: “List the name and number of followers for each user.”
SQL query: select name, followers from user_profiles
In the training data space, the mapping between questions and SQL queries is many-to-many:
- A SQL query can be mapped to many different questions in natural language; for example, the above query semantics can be expressed by: “show me the names and numbers of followers per user”, “how many followers are there for each user?” etc.
- SQL syntax is highly versatile, and almost every question can be represented in SQL in multiple ways. The simplest example are different orderings of WHERE clauses. On a more advanced stance, everyone who has done SQL query optimisation will know that many roads lead to the same result, and semantically equivalent queries might have completely different syntax.
The manual collection of training data for Text2SQL is particularly tedious. It not only requires SQL mastery on the part of the annotator, but also more time per example than more general linguistic tasks such as sentiment analysis and text classification. To ensure a sufficient quantity of training examples, data augmentation can be used — for example, LLMs can be used to generate paraphrases for the same question. [3] provides a more complete survey of Text2SQL data augmentation techniques.
1.2 Enriching the prompt with database information
Text2SQL is an algorithm at the interface between unstructured and structured data. For optimal performance, both types of data need to be present during training and prediction. Specifically, the algorithm has to know about the queried database and be able to formulate the query in such a way that it can be executed against the database. This knowledge can encompass:
- Columns and tables of the database
- Relations between tables (foreign keys)
- Database content
There are two options for incorporating database knowledge: on the one hand, the training data can be restricted to examples written for the specific database, in which case the schema is learned directly from the SQL query and its mapping to the question. This single-database setting allows to optimise the algorithm for an individual database and/or company. However, it kills off any ambitions for scalability, since the model needs to be fine-tuned for every single customer or database. Alternatively, in a multi-database setting, the database schema can be provided as part of the input, allowing the algorithm to “generalise” to new, unseen database schemas. While you will absolutely need to go for this approach if you want to use Text2SQL on many different databases, keep in mind that it requires considerable prompt engineering effort. For any reasonable business database, including the full information in the prompt will be extremely inefficient and most probably impossible due to prompt length limitations. Thus, the function responsible for prompt formulation should be smart enough to select a subset of database information which is most “useful” for a given question, and to do this for potentially unseen databases.
Finally, database structure plays a crucial role. In those scenarios where you have enough control over the database, you can make your model’s life easier by letting it learn from an intuitive structure. As a rule of thumb, the more your database reflects how business users talk about the business, the better and faster your model can learn from it. Thus, consider applying additional transformations to the data, such as assembling normalised or otherwise dispersed data into wide tables or a data vault, naming tables and columns in an explicit and unambiguous way etc. All business knowledge that you can encode up-front will reduce the burden of probabilistic learning on your model and help you achieve better results.
2. Algorithm
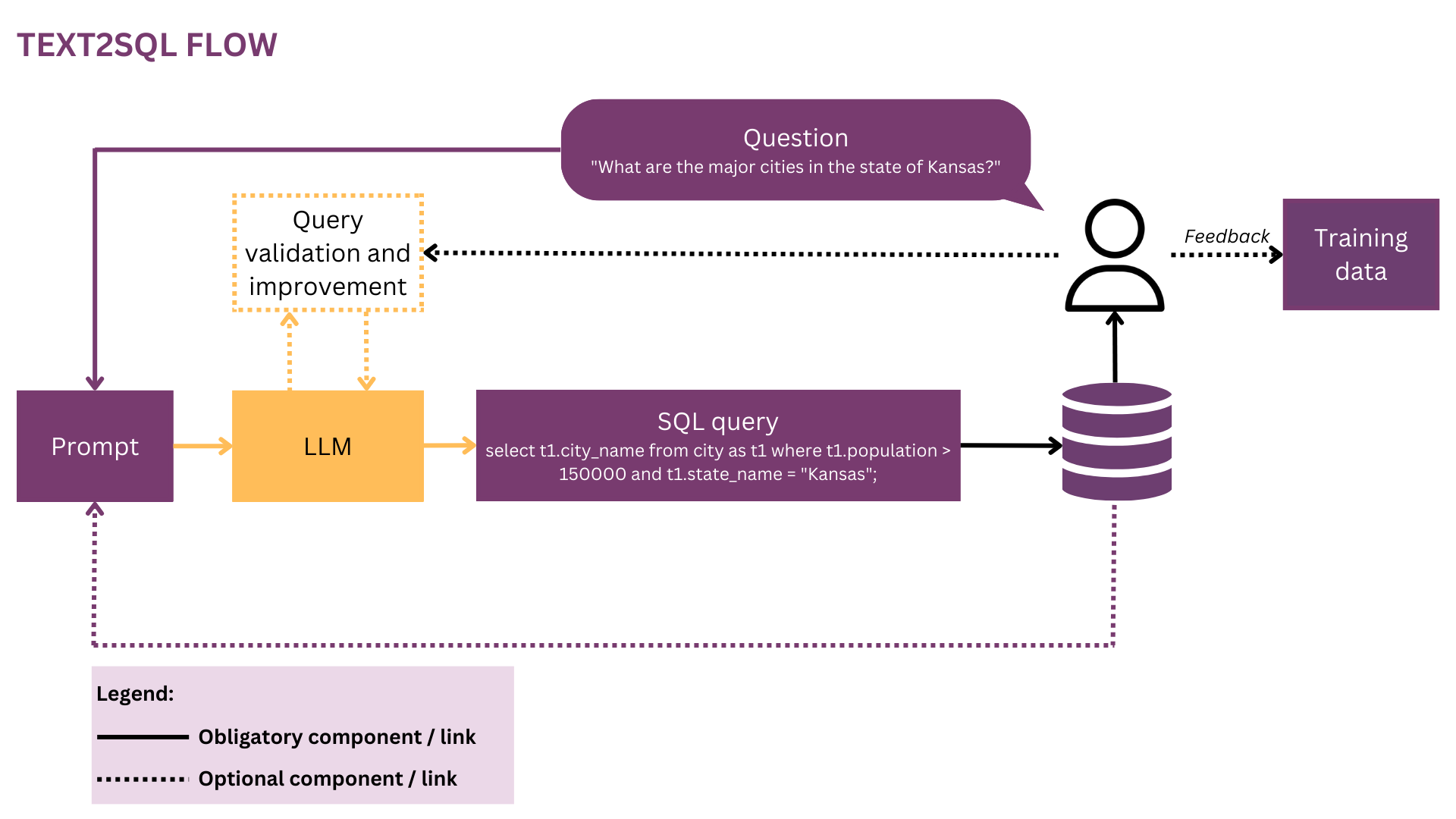
Figure 3: In this Text2SQL representation, algorithm-related elements and relations are marked in yellow.
Text2SQL is a type of semantic parsing — the mapping of texts to logical representations. Thus, the algorithm has not only to “learn” natural language, but also the target representation — in our case, SQL. Specifically, it has to acquire and the following bits of knowledge:
- SQL syntax and semantics
- Database structure
- Natural Language Understanding (NLU)
- Mapping between natural language and SQL queries (syntactic, lexical and semantic)
2.1 Solving linguistic variability in the input
At the input, the main challenge of Text2SQL lies in the flexibility of language: as described in the section Format and structure of the data (link!), the same question can be paraphrased in many different ways. Additionally, in the real-life conversational context, we have to deal with a number of issues such as spelling and grammar mistakes, incomplete and ambiguous inputs, multilingual inputs etc.

Figure 4: The Text2SQL algorithm has to deal with many different variants of a question
LLMs such as the GPT models, T5 and CodeX are coming closer and closer to solving this challenge. Learning from huge quantities of diverse text, they learn to deal with a large number of linguistic patterns and irregularities. In the end, they become able to generalise over questions which are semantically similar despite having different surface forms. LLMs can be applied out-of-the-box (zero-shot) or after fine-tuning. The former, while convenient, leads to lower accuracy. The latter requires more skill and work, but can significantly increase accuracy.
In terms of accuracy, as expected, the best-performing models are the latest models of the GPT family including the CodeX models. In April 2023, GPT-4 led to a dramatic accuracy increase of more than 5% over the previous state-of-the-art and achieved an accuracy of 85.3% (оn the metric “execution with values”).[4] In the open-source camp, initial attempts at solving the Text2SQL puzzle were focussed on auto-encoding models such as BERT, which excel at NLU tasks.[5, 6, 7] However, amidst the hype around generative AI, recent approaches focus on autoregressive models such as the T5 model. T5 is pre-trained using multi-task learning and thus easily adapts to new linguistic tasks, incl. different variants of semantic parsing. However, autoregressive models have an intrinsic flaw when it comes to semantic parsing tasks: they have an unconstrained output space and no semantic guardrails that would constrain their output, which means they can get stunningly creative in their behaviour. While this is amazing stuff for generating free-form content, it is a nuisance for tasks like Text2SQL where we expect a constrained, well-structured target output.
2.2 Query validation and improvement
To constrain the LLM output, we can introduce additional mechanisms for validating and improving the query. This can be implemented as an extra validation step, as proposed in the PICARD system.[8] PICARD uses a SQL parser that can verify whether a partial SQL query can lead to a valid SQL query after completion. At each generation step by the LLM, tokens that would invalidate the query are rejected, and the highest-probability valid tokens are kept. Being deterministic, this approach ensures 100% SQL validity as long as the parser observes correct SQL rules. It also decouples the query validation from the generation, thus allowing to maintain both components independently of one another and to upgrade and modify the LLM.
Another approach is to incorporate structural and SQL knowledge directly into the LLM. For example, Graphix [9] uses graph-aware layers to inject structured SQL knowledge into the T5 model. Due to the probabilistic nature of this approach, it biases the system towards correct queries, but doesn’t provide a guarantee for success.
Finally, the LLM can be used as a multi-step agent that can autonomously check and improve the query.[10] Using multiple steps in a chain-of-thought prompt, the agent can be tasked to reflect on the correctness of its own queries and improve any flaws. If the validated query can still not be executed, the SQL exception traceback can be passed to the agent as an additional feedback for improvement.
Beyond these automated methods which happen in the backend, it is also possible to involve the user during the query checking process. We will describe this in more detail in the section on User experience (link!).
2.3 Evaluation
To evaluate our Text2SQL algorithm, we need to generate a test (validation) dataset, run our algorithm on it and apply relevant evaluation metrics on the result. A naive dataset split into training, development and validation data would be based on question-query pairs and lead to suboptimal results. Validation queries might be revealed to the model during training and lead to an overly optimistic view on its generalisation skills. A query-based split, where the dataset is split in such a way that no query appears both during training and during validation, provides more truthful results.
In terms of evaluation metrics, what we care about in Text2SQL is not to generate queries that are completely identical to the gold standard. This “exact string match” method is too strict and will generate many false negatives, since different SQL queries can lead to the same returned dataset. Instead, we want to achieve high semantic accuracy and evaluate whether the predicted and the “gold standard” queries would always return the same datasets. There are three evaluation metrics that approximate this goal:
- Exact-set match accuracy: the generated and target SQL queries are split into their constituents, and the resulting sets are compared for identity.[11] The shortcoming here is that it only accounts for order variations in the SQL query, but not for more pronounced syntactic differences between semantically equivalent queries.
- Execution accuracy: the datasets resulting from the generated and target SQL queries are compared for identity. With good luck, queries with different semantics can still pass this test on a specific database instance. For example, assuming a database where all users are aged over 30, the following two queries would return identical results despite having different semantics:
- select * from user
- select * from user where age > 30
- Test-suite accuracy: test-suite accuracy is a more advanced and less permissive version of execution accuracy. For each query, a set (”test suite”) of databases is generated that are highly differentiated with respect to the variables, conditions and values in the query. Then, execution accuracy is tested on each of these databases. While requiring additional effort to engineer the test-suite generation, this metric also significantly reduces the risk of false positives in the evaluation.[12]
3. Algorithm
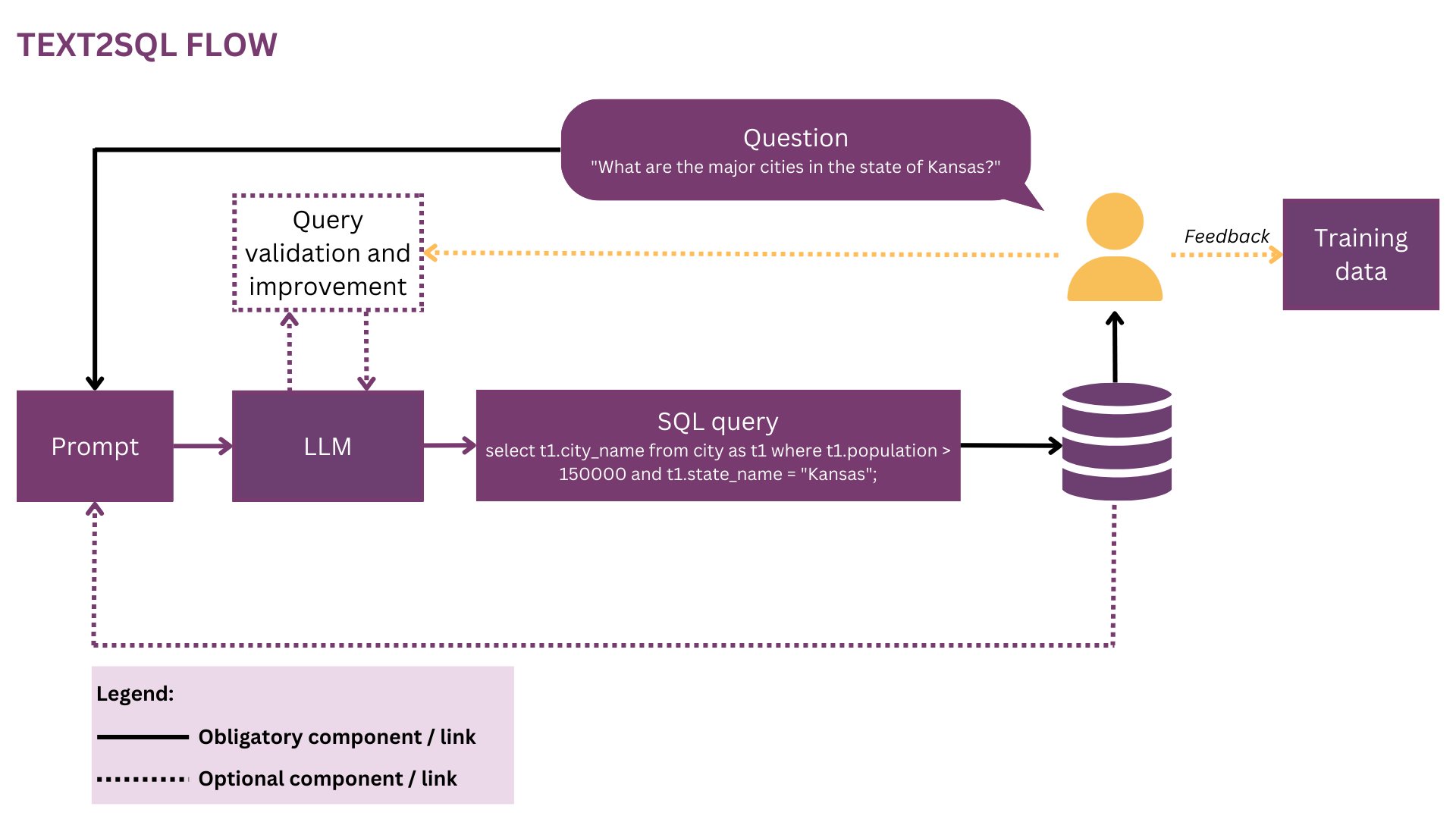
Figure 5: In this Text2SQL representation, UX-related elements and relations are marked in yellow.
The current state-of-the-art of Text2SQL doesn’t allow a completely seamless integration into production systems — instead, it is necessary to actively manage the expectations and the behaviour of the user, who should always be aware that she is interacting with an AI system.
3.1 Failure management
Text2SQL can fail in two modes, which need to be caught in different ways:
- SQL errors: the generated query is not valid — either the SQL is invalid, or it cannot be executed against the specific database due to lexical or semantic flaws. In this case, no result can be returned to the user.
- Semantic errors: the generated query is valid but it does not reflect the semantics of the question, thus leading to a wrong returned dataset.
The second mode is particularly tricky since the risk of “silent failures” — errors that go undetected by the user — is high. The prototypical user will have neither the time nor the technical skill to verify the correctness of the query and/or the resulting data. When data is used for decision making in the real world, this kind of failure can have devastating consequences. To avoid this, it is critical to educate users and establish guardrails on a business level that limit the potential impact, such as additional data checks for decisions with a higher impact. On the other hand, we can also use the user interface to manage the human-machine interaction and help the user detect and improve problematic requests.
3.2 Human-machine interaction
Users can get involved with your AI system with different degrees of intensity. More interaction per request can lead to better results, but it also slows down the fluidity of the user experience. Besides the potential negative impact of erroneous queries and results, also consider how motivated your users will be to provide back-and-forth feedback in order to get more accurate results and also help improve the product in the long term.
The easiest and least engaging way is to work with confidence scores. While the naive calculation of confidence as an average of the probabilities of the generated tokens is overly simplistic, more advanced methods like verbalised feedback can be used.[13] The confidence can be displayed in the interface and highlighted with an explicit alert in case it is dangerously low. This way, the responsibility of an appropriate follow-up in the “real world” — be it a rejection, acceptance or an additional check of the data — lands on the shoulders of your user. While this is a safe bet for you as a vendor, transferring this work to the user can also reduce the value of your product.
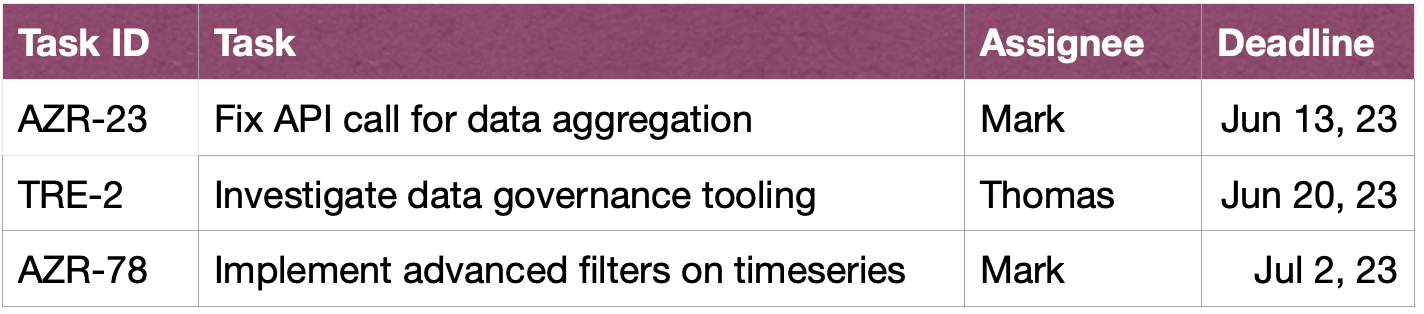
A second possibility is to engage the user in a clarification dialogue in the case of low-confidence, ambiguous or otherwise suspicious queries. For example, your system might suggest orthographic or grammar corrections to the input and ask to disambiguate specific words or grammatical structures. It might also allow the user to proactively ask for corrections in the query:[14]
USER: Show me John’s tasks in this sprint.
ASSISTANT: Would you like to see tasks John created, or those he is working on?
USER: tasks John created
ASSISTANT: Ok, here are the task IDs:

USER: Thanks, I would also like to see more information about the tasks. Please also sort by urgency.
ASSISTANT: Sure, here are the tasks along with short descriptions, assignees and deadlines, sorted by deadline.
Finally, to ease the understanding of queries by the user, your system can also provide an explicit textual reformulation of the query and ask the user to either confirm or correct it.[15]
4. Non-functional requirements
In this section, we discuss the specific non-functional requirements for Text2SQL as well as the trade-offs between them. We will focus on the six requirements that seem most important for the task: accuracy, scalability, speed, explainability, privacy and adaptability over time.
4.1 Accuracy
For Text2SQL, the requirements on accuracy are high. First, Text2SQL is typically applied in a conversation setting where predictions are made one-by-one. Thus, the “Law of large numbers” which typically helps balance off the error in batched predictions, does not help. Second, syntactic and lexical validity is a “hard” condition: the model has to generate a well-formed SQL query, potentially with complex syntax and semantics, otherwise the request cannot be executed against the database. And if this goes well and the query can be executed, it can still contain semantic errors and lead to a wrong returned dataset (cf. section 3.1 Failure management).
4.2 Scalability
The main scalability considerations are whether you want to apply Text2SQL on one or multiple databases — and in the latter case, whether the set of databases is known and closed. If yes, you will have an easier time since you can include the information about these databases during training. However, in a scenario of a scalable product — be it a standalone Text2SQL application or an integration into an existing data product — your algorithm has to cope with any new database schema on the fly. This scenario also doesn’t give you the opportunity to transform the database structure to make it more intuitive for learning (link!). All of this leads to a heavy trade-off with accuracy, which might also explain why current Text2SQL providers that offer ad-hoc querying of new databases have not yet achieve a significant market penetration.
4.3 Speed
Since Text2SQL requests will typically be processed online in a conversation, the speed aspect is important for user satisfaction. On the positive side, users are often aware of the fact that data requests can take a certain time and show the required patience. However, this goodwill can be undermined by the chat setting, where users subconsciously expect human-like conversation speed. Brute-force optimisation methods like reducing the size of the model might have an unacceptable impact on accuracy, so consider inference optimisation to satisfy this expectation.
4.4 Explainability and transparency
In the ideal case, the user can follow how the query was generated from the text, see the mapping between specific words or expressions in the question and the SQL query etc. This allows to verify the query and make any adjustments when interacting with the system. Besides, the system could also provide an explicit textual reformulation of the query and ask the user to either confirm or correct it.
4.5 Privacy
The Text2SQL function can be isolated from query execution, so the returned database information can be kept invisible. However, the critical question is how much information about the database is included in the prompt. The three options (by decreasing privacy level) are:
- No information
- Database schema
- Database content
Privacy trades off with accuracy — the less constrained you are in including useful information in the prompt, the better the results.
4.6 Adaptability over time
To use Text2SQL in a durable way, you need to adapt to data drift, i. e. the changing distribution of the data to which the model is applied. For example, let’s assume that the data used for initial fine-tuning reflects the simple querying behaviour of users when they start using the BI system. As time passes, information needs of users become more sophisticated and require more complex queries, which overwhelm your naive model. Besides, the goals or the strategy of a company change might also drift and direct the information needs towards other areas of the database. Finally, a Text2SQL-specific challenge is database drift. As the company database is extended, new, unseen columns and tables make their way into the prompt. While Text2SQL algorithms that are designed for multi-database application can handle this issue well, it can significantly impact the accuracy of a single-database model. All of these issues are best solved with a fine-tuning dataset that reflects the current, real-world behaviour of users. Thus, it is crucial to log user questions and results, as well as any associated feedback that can be collected from usage. Additionally, semantic clustering algorithms, for example using embeddings or topic modelling, can be applied to detect underlying long-term changes in user behaviour and use these as an additional source of information for perfecting your fine-tuning dataset
Conclusion
Let’s summarise the key points of the article:
- Text2SQL allows to implement intuitive and democratic data access in a business, thus maximising the value of the available data.
- Text2SQL data consist of questions at the input, and SQL queries at the output. The mapping between questions and SQL queries is many-to-many.
- It is important to provide information about the database as part of the prompt. Additionally, the database structure can be optimised to make it easier for the algorithm to learn and understand it.
- On the input, the main challenge is the linguistic variability of natural-language questions, which can be approached using LLMs that were pre-trained on a wide variety of different text styles
- The output of Text2SQL should be a valid SQL query. This constraint can be incorporated by “injecting” SQL knowledge into the algorithm; alternatively, using an iterative approach, the query can be checked and improved in multiple steps.
- Due to the potentially high impact of “silent failures” which return wrong data for decision-making, failure management is a primary concern in the user interface.
- In an “augmented” fashion, users can be actively involved in iterative validation and improvement of SQL queries. While this makes the application less fluid, it also reduces failure rates, allows users to explore data in a more flexible way and creates valuable signals for further learning.
- The major non-functional requirements to consider are accuracy, scalability, speed, explainability, privacy and adaptability over time. The main trade-offs consist between accuracy on the one hand, and scalability, speed and privacy on the other hand.
References
[1] Ken Van Haren. 2023. Replacing a SQL analyst with 26 recursive GPT prompts
[2] Nitarshan Rajkumar et al. 2022. Evaluating the Text-to-SQL Capabilities of Large Language Models
[3] Naihao Deng et al. 2023. Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect
[4] Mohammadreza Pourreza et al. 2023. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction
[5] Victor Zhong et al. 2021. Grounded Adaptation for Zero-shot Executable Semantic Parsing
[6] Xi Victoria Lin et al. 2020. Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing
[7] Tong Guo et al. 2019. Content Enhanced BERT-based Text-to-SQL Generation
[8] Torsten Scholak et al. 2021. PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models
[9] Jinyang Li et al. 2023. Graphix-T5: Mixing Pre-Trained Transformers with Graph-Aware Layers for Text-to-SQL Parsing
[10] LangChain. 2023. LLMs and SQL
[11] Tao Yu et al. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task
[12] Ruiqi Zhong et al. 2020. Semantic Evaluation for Text-to-SQL with Distilled Test Suites
[13] Katherine Tian et al. 2023. Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback
[14] Braden Hancock et al. 2019. Learning from Dialogue after Deployment: Feed Yourself, Chatbot!
[15] Ahmed Elgohary et al. 2020. Speak to your Parser: Interactive Text-to-SQL with Natural Language Feedback