In this article, I explain the general idea behind word embeddings and illustrate it using a real-life problem of competitive intelligence.
The big idea
To apply Deep Learning to text data, we first need to transform the data into a mathematical representation – typically, a vector. The traditional representation is the so-called one-hot encoding. Here, each word becomes a unique vector of the length of the full vocabulary. This vector consists of many “0”s and a single “1” at the position which uniquely identifies the word. Let's say we have a toy vocabulary consisting of four words - McKinsey, BCG, KPMG and PwC. They would have the following encoding: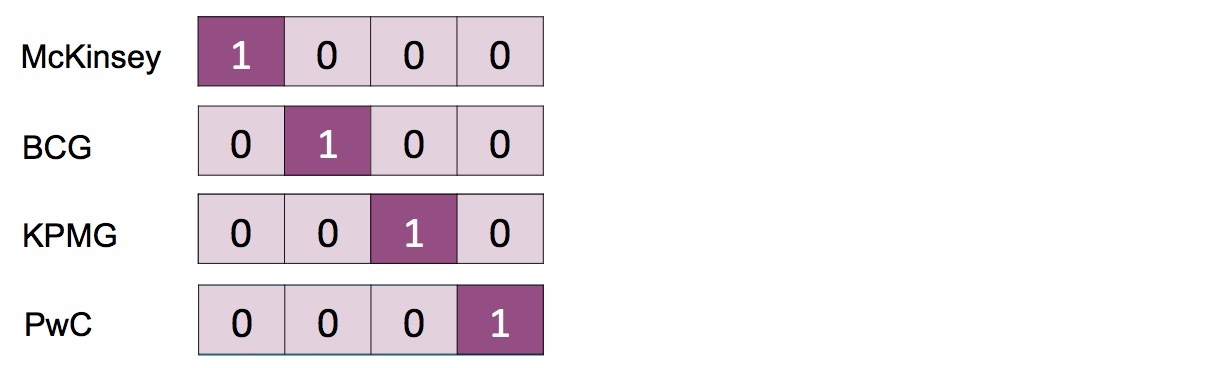
There are two issues with this representation. First, the vector can get offensively long – a typical vocabulary consists of tens or even hundreds thousands of words. Thus, this representation is extremely expensive in computational terms. Second, one-hot encodings are discrete representations and do not capture any similarities or more nuanced relations between words.
Word embeddings offer a more succinct mathematical representation. They made their debut in 2013 in a paper by Mikolov et al [2]. The underlying assumption is that the meaning of a word is shaped by its contexts. Word embeddings condense the information about possible contexts into a more compact form. They are highly efficient in taming semantic complexity and thus allow us to make sense of large quantities of text data. In our toy example, while still uniquely encoding every word, word embeddings would also distill the fact that McKinsey and BCG focus on strategy (0.76 and 0.88), whereas KPMG and PwC concentrate on accounting (0.83 and 0.82):

On top of all, this additional information comes at half price - the size of the matrix is half the size of the one-hot encoding.
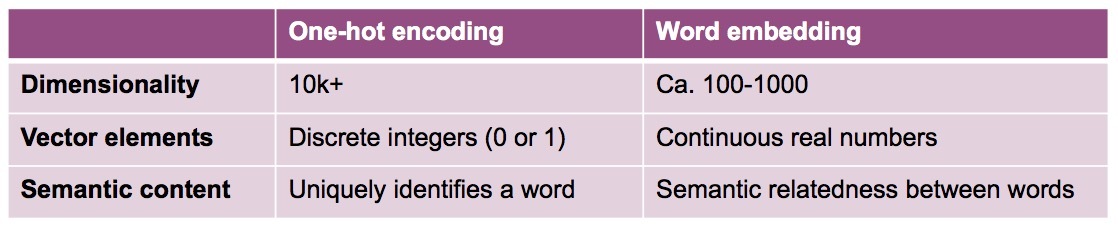
The following table summarizes the differences between one-hot encodings and word embeddings:
How it works
At a practical level, training and using word embeddings is a fairly uncomplicated task. The training data comes almost for free - it is just a large collection of texts. This raw data is transformed into labeled training data, where words are the training labels, and their contexts are the input examples, or vice versa. Then, a neural network is trained to predict the training labels from the input examples. The first layer of this network is saved as the word embeddings and can be reused for actual NLP tasks, such as sentiment analysis, text classification and entity recognition. The assumption is that a network layer that performs well for language prediction will also perform well for other NLP tasks.On the practical level, word2vec, the original architecture for training word embeddings, has been followed by a range of new training paradigms and frameworks, incl. Glove, FastText, ELMo and BERT. We will be looking at the short but impressive history of word embeddings in a subsequent post.
Using word embeddings for instant competitive intelligence
Word embeddings are predestined for any tasks that are based on the notion of similarity, such as recommendation, search and question answering. Suppose you want to know more about your competitors. Thus, you are looking for companies that are similar to your own. Let’s make our toy example real: we are interested in competitors of McKinsey and want to see if word embeddings can extract information matching our domain knowledge.We train word embeddings on a large corpus of recent business news and find out which words are closest to McKinsey: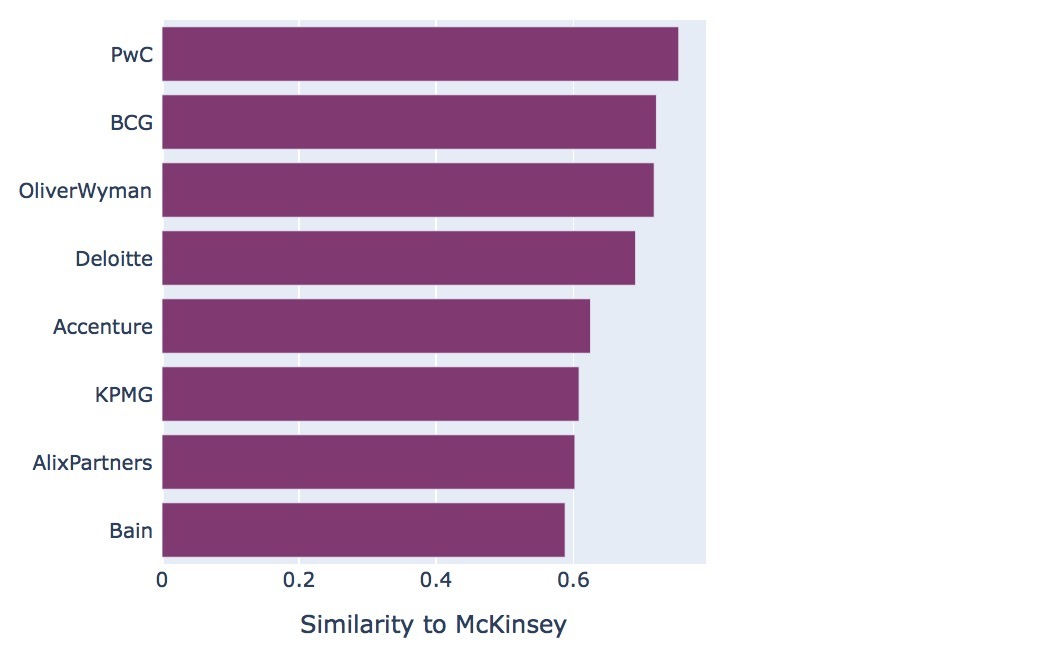
The list mostly contains consulting and research companies. So far, our representation is one-dimensional - but we can do much more with word embeddings. Let's look at a two-dimensional representation, which not only captures the similarity to McKinsey, but also the similarities between all other concepts in the chart:

But wait a minute - what do the two dimensions actually mean? The chart leaves a lot of room for interpretation since the notion of „similarity“ is very abstract. It includes all semantic contexts and features from our data – too many to be enumerated and conceptualized by our brains - and reduces them to two dimensions. To get a more concrete – albeit less exhaustive – representation, we will „fix“ the axes to specific aspects. Let’s say we want to consider how the companies relate to the two dimensions „Accounting“ and „Strategy“. We fix the x-axis to the word embedding for „Accounting“, and the y-axis to the word embedding for „Strategy“. The resulting representation with clearly defined axes bring us back into our comfort zone:
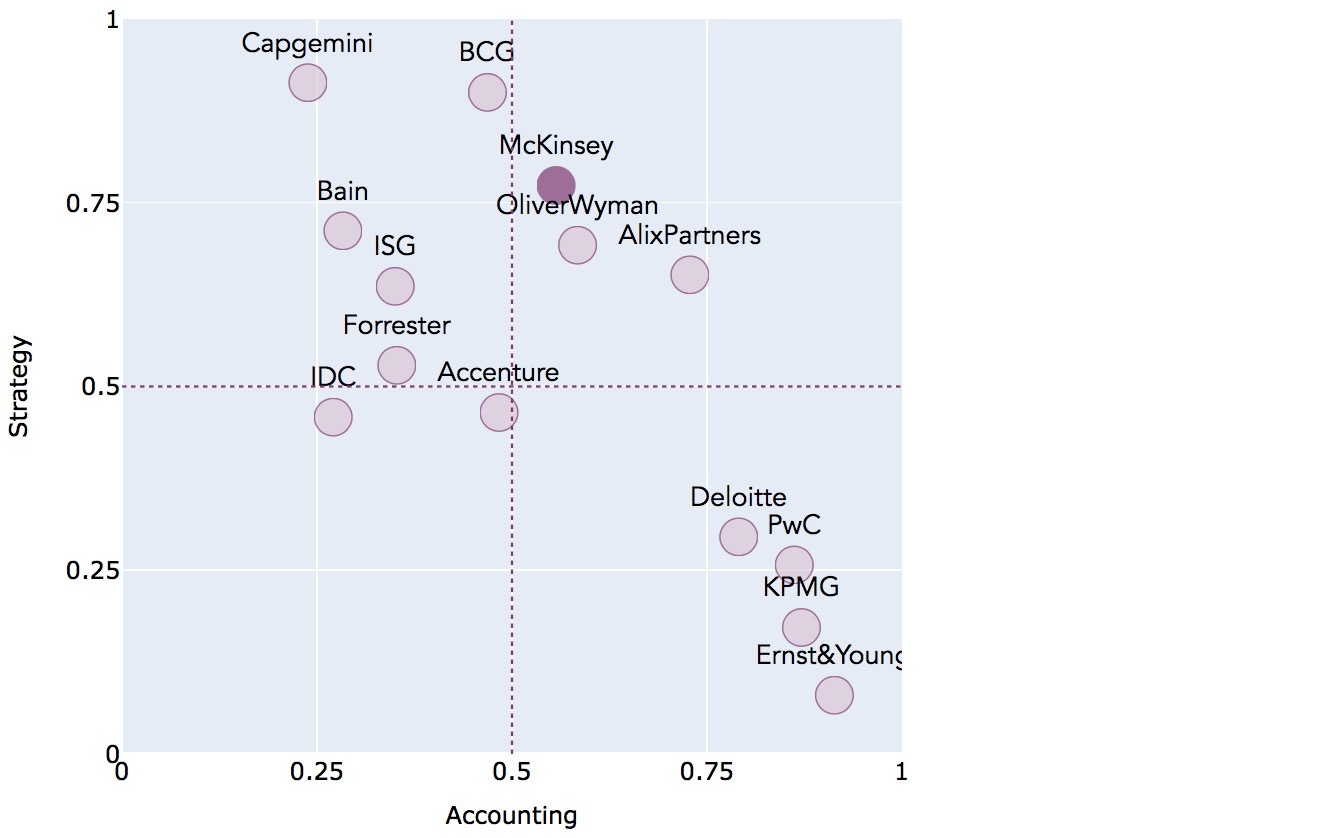
Let's read the data. The „Big 4“ – Deloitte, PwC, KPMG and Ernst&Young – clearly cluster highly on "Accounting". Capgemini, McKinsey, Bain and BCG are highest in terms of "Strategy". This matches our commonsense knowledge and arms us with additional confidence into the obtained results.
The benefits
Let's first sum up the practical benefits. Word embeddings can boost any NLP task solved with Deep Learning, such as sentiment analysis, named entity recognition and text classification. Training data comes almost for free in the form of naturally available text data. Word embeddings have fewer dimensions than the traditional one-hot encodings and can thus be processed with high speed.The most compelling and strategic value of word embeddings is their ability to capture huge quantities of semantic information at a scale that is hardly accessible to human reasoning. With the right approach, word embeddings can be leveraged as a tool for dynamically extracting knowledge and learning from ever-growing and changing quantities of text data.
Notes and references
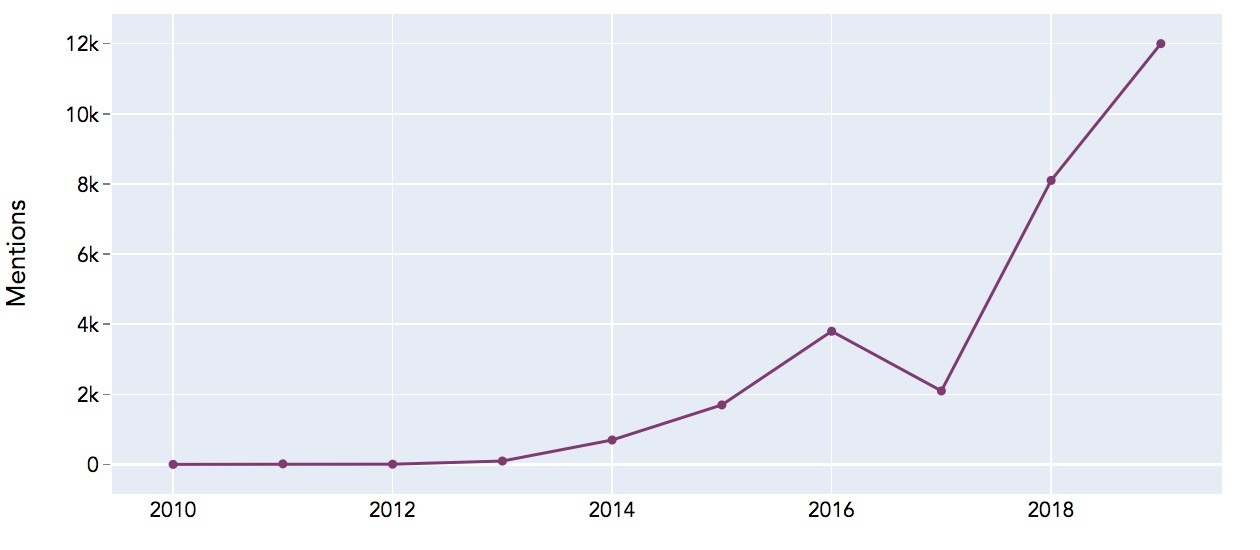
[1] The basis for this analysis are ca. 3000 papers published at the leading NLP conferences (ACL, COLING, EMNLP, NAACL) since 2009.[2] Mikolov, T.; Chen, K.; Corrado, G. & Dean, J. (2013), 'Efficient Estimation of Word Representations in Vector Space', CoRRabs/1301.3781.